Featured Project
FeaturedGenerative AIRAG
Claims Document Intelligence
A RAG-powered decision-support assistant for Australian Workers Compensation queries, built by a practising Claims Advisor at Suncorp Group. Grounds LLM answers in authoritative legislation and policy documents with inline source citations and a 20-question evaluation harness.
Domain
Workers Compensation Insurance
Stack
Python · LlamaIndex · ChromaDB · Anthropic-Claude · Streamlit · Sentence Transformers · RAG
Published
April 2026
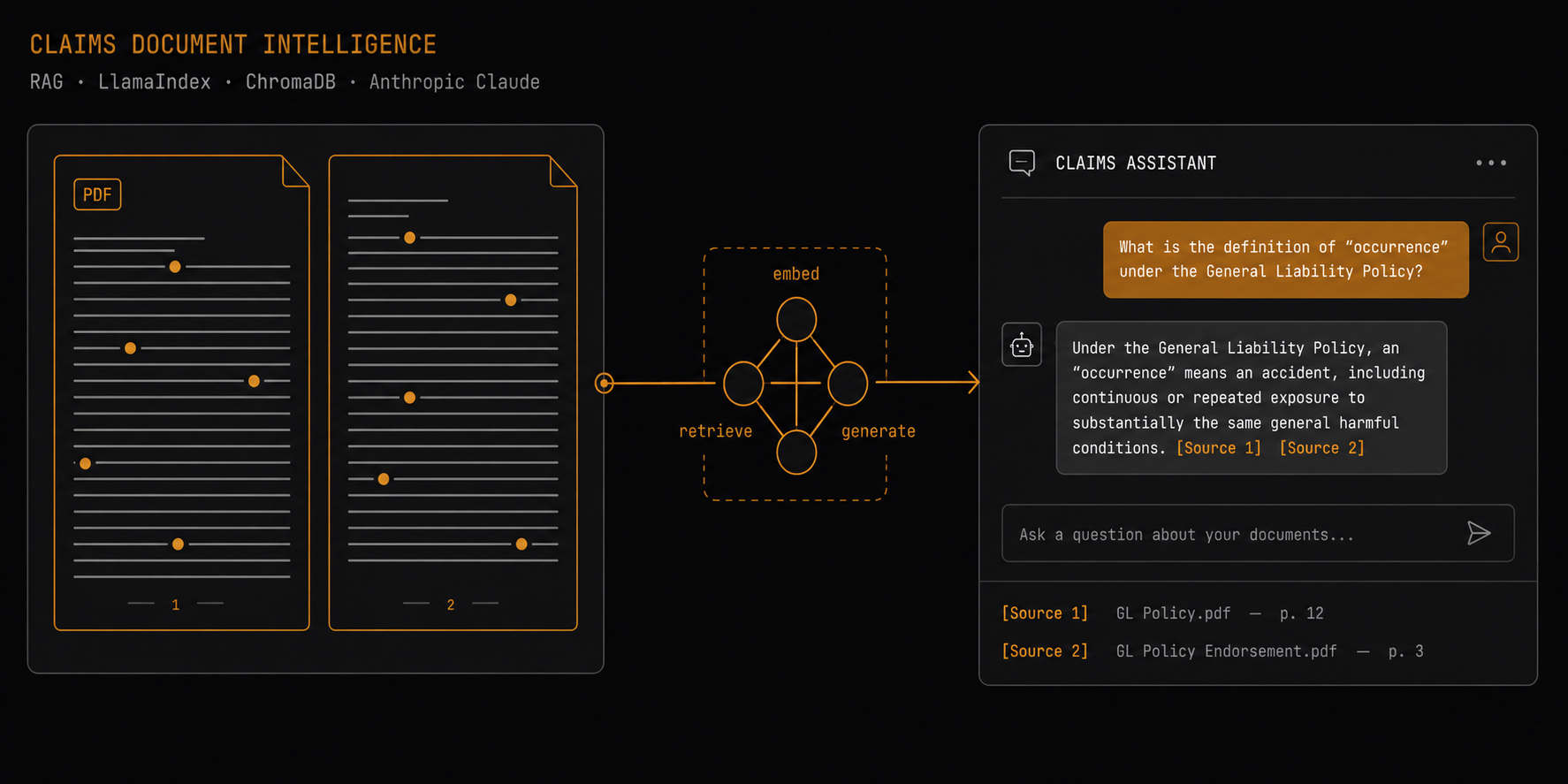
As a Claims Advisor at Suncorp Group, I spend significant time navigating hundreds of pages of legislation, regulatory guidelines, and policy documents to answer procedural questions. This project prototypes a Retrieval-Augmented Generation (RAG) system that grounds LLM responses in a curated corpus of authoritative documents — with inline citations visible to the user, so every factual claim can be verified against the primary source.
The target user is a Claims Advisor or case manager triaging legislative and policy questions. The system is designed as a decision-support tool, not an autonomous agent and not a replacement for legal or actuarial advice.
What it does
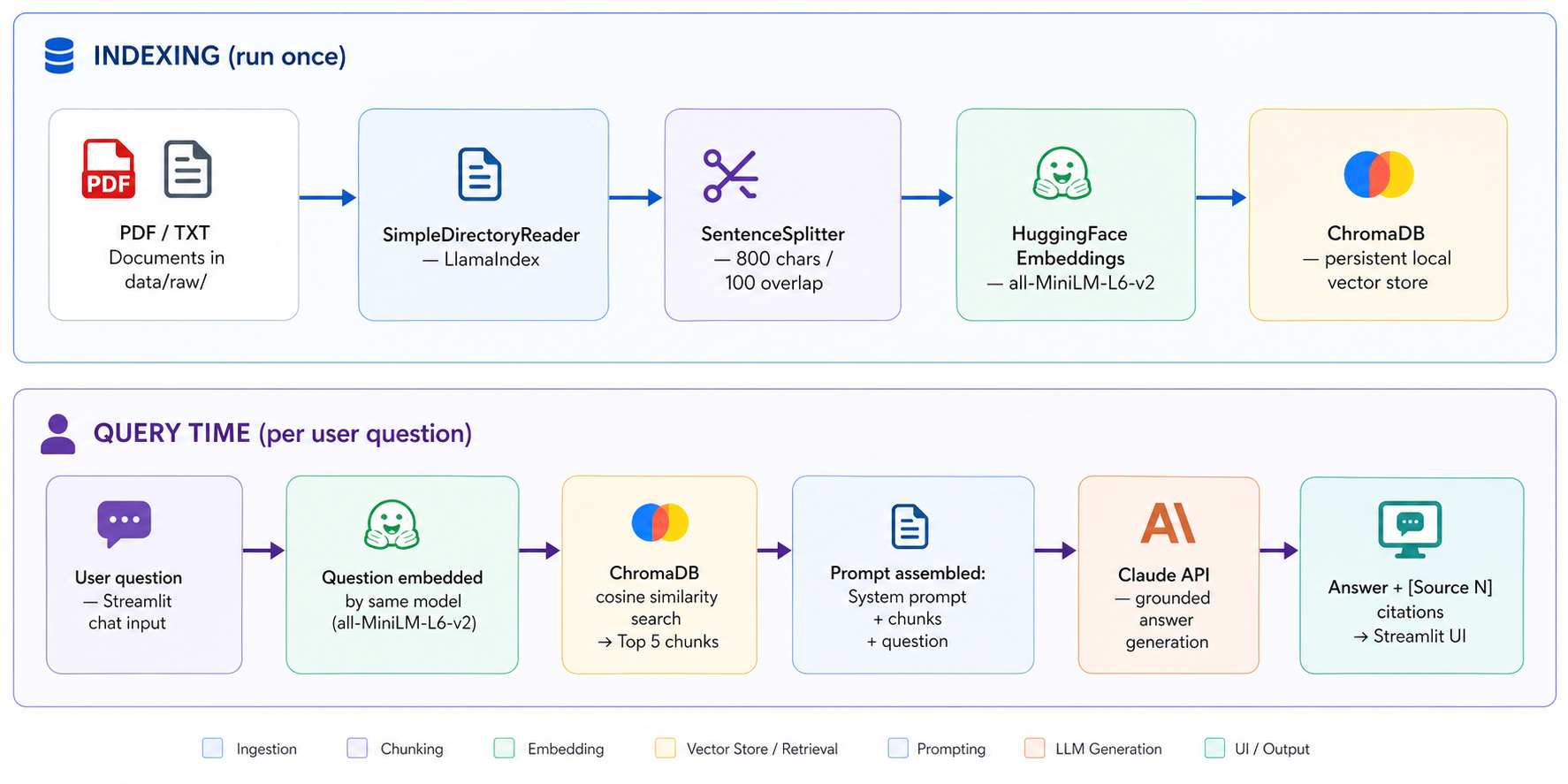
The system ingests PDF documents — the ACT Workers Compensation Act 1951, Workers Compensation Regulation 2002, SIRA Standards of Practice, Comcare return-to-work guidelines, APRA GPS 320 (Actuarial and Related Matters), the National Return to Work Strategy 2020–2030, and a set of synthetic de-identified claim narratives — into a local ChromaDB vector store.
At query time, the user's question is embedded using the same local model
(sentence-transformers/all-MiniLM-L6-v2), the top 5 semantically similar
chunks are retrieved, and a grounded answer is generated via Claude with
inline [Source N] citations. Retrieved passages are displayed alongside the
answer so the user can verify every claim.
The system declines to answer when the corpus does not contain sufficient
information. Grounding is enforced in the system prompt — the LLM is explicitly instructed not to use outside knowledge and to cite sources for
every factual claim.
Tech Stack
Orchestration: LlamaIndex — mature RAG framework with clean pipeline abstractions.
Embeddings: sentence-transformers/all-MiniLM-L6-v2 — free, runs fully locally, 384-dimensional vectors. No data leaves the machine during indexing.
Vector DB: ChromaDB — zero-infrastructure persistent local store.
LLM: Anthropic Claude (claude-haiku-4-5) — strong instruction-following for
grounded Q&A with reliable refusal when sources are insufficient.
UI: Streamlit — commercial LLM-style interface with a centred landing state,
example question cards, and expandable source citation panels.
Evaluation: Custom Python harness with Pandas — lexical term coverage and source match rate across 20 hand-labelled Q&A pairs.
Key Architecture Decisions
Chunk size 800 chars / 100 overlap. Tested at 500, 800, and 1,200 characters.
Legislative text has self-contained clauses of 300–600 characters — 800 captures the clause plus immediate context without pulling in unrelated provisions. The 100-character overlap prevents clause boundaries from splitting awkwardly.
Top-k = 5. Fewer missed relevant context on multi-clause questions; more diluted the LLM context and increased hallucination risk on edge cases.
Temperature = 0.1. Keeps the LLM close to source material — important when users may quote the answer to a stakeholder or include it in a formal record.
Local embeddings over API embeddings. In a production deployment, claimant-adjacent queries should not leave the organisation's infrastructure. Running the embedding model locally makes the architecture compatible with private deployment from the outset.
Architecture Diagram
Evaluation
A hand-labelled set of 20 questions was used across four categories: factual
legislative, procedural, conceptual, and scenario-based (against synthetic claim narratives), plus two intentional out-of-scope questions to test grounding discipline.
Results: 73% mean term coverage · 100% source match rate · 11/20 perfect scores · 2/2 out-of-scope refusals correctly handled.
The single zero-coverage result (q16) documents a vocabulary collision failure —
where high-frequency return-to-work vocabulary in the Workers Compensation Act outcompeted the synthetic claim narrative in cosine similarity, preventing the system from locating a specific claim ID. The generated answer correctly declined rather than fabricating a response. Mitigations for a production system include hybrid BM25 + dense retrieval and metadata-filtered routing for record lookups.
The evaluation harness is reproducible: running python -m eval.run_eval regenerates both the CSV results and the term coverage bar chart.
Responsible AI considerations
Grounding is enforced by the system prompt — the LLM is instructed to refuse when sources are insufficient, cite every factual claim, and not draw on outside knowledge.
All retrieved source passages are visible in the UI. Users can expand the citation panel for any answer and verify claims against the original document.
The 10 synthetic claim narratives used for evaluation are clearly marked as fictional. No real claimant data, employer names, or incident details were used at any stage.
The Streamlit UI includes an explicit disclaimer: the tool is for decision support
only and is not legal, medical, or actuarial advice.
What I'd build next
- —Hybrid retrieval (BM25 + dense vector search) to resolve vocabulary collision failures on specific record lookups.
- —Semantic evaluation with RAGAS — replacing lexical term coverage with faithfulness and answer relevance scores that measure whether answers are semantically grounded in the retrieved context.
- —Agent layer with tool calling — a calculator tool for entitlement arithmetic and a date tool for weeks-since-injury calculations, moving the system toward an interactive case support tool.
- —Metadata-filtered retrieval — routing record-lookup queries to structured search and policy questions to the vector store.
KEY INSIGHTS
100% source match rate
The retrieval system correctly identified the right source document for all 20 evaluation questions — confirming the embedding and vector search pipeline is architecturally sound.
Insight 2: Grounding holds on out-of-scope queries
Both intentional out-of-scope questions (RBA interest rates, 2024 election) were correctly declined without fabrication — the most important safety property for a tool used in a regulated insurance environment.
Vocabulary collision documented
The single retrieval failure (q16) reveals a known RAG limitation: dense legislative vocabulary outcompetes a smaller synthetic source in cosine similarity. The system declined rather than hallucinating — and the failure is fully documented with three production mitigations.
Built by a practising Claims Advisor
The domain knowledge shaping every design decision — chunk size, corpus selection, system prompt grounding rules, responsible AI framing — comes from daily operational exposure to the ACT Workers Compensation Act, not from studying insurance from the outside.